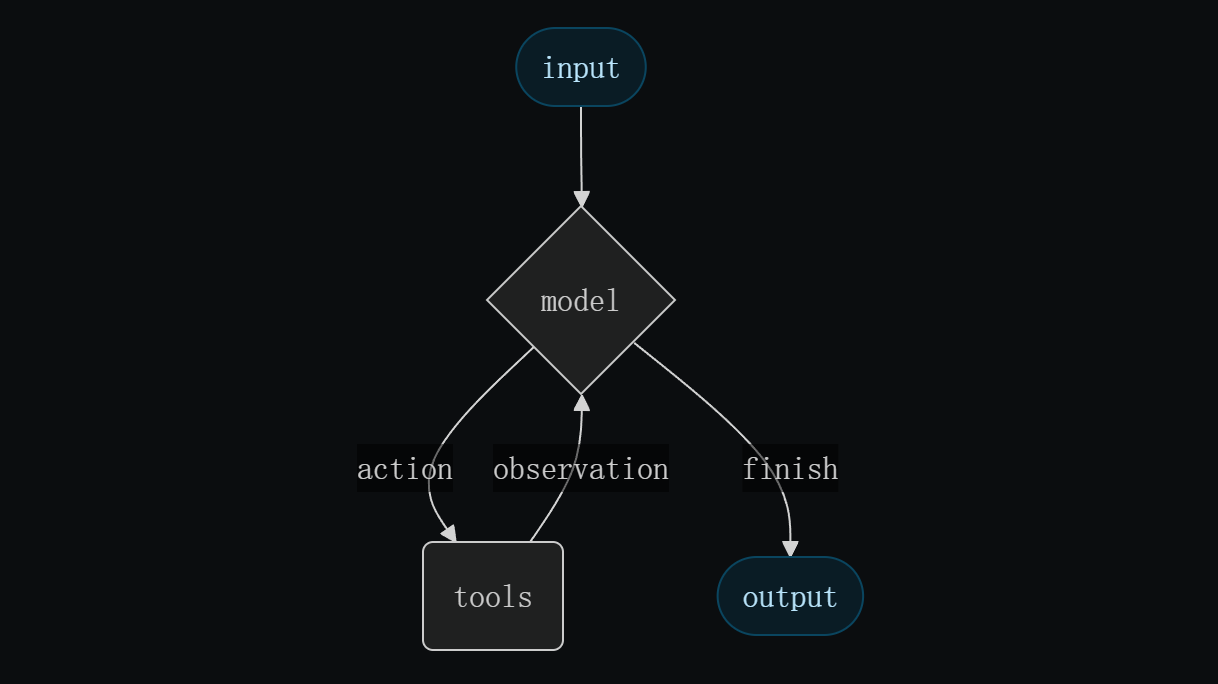
LangChain 1.0 对框架架构进行根本性重置,将 LangGraph 确立为底层运行框架,通过 create_agent() 统一所有 Agent 的创建入口。
create_agent 创建 Agent
LangChain 1.0 提供的 create_agent() 接口可以用极简方式创建一个完整的、可运行的智能体系统。create_agent 会在内部使用 LangGraph 构建一个基于图结构的 Agent Runtime:
- 节点(Node):代表执行步骤,例如模型调用节点、工具执行节点或中间件节点
- 边(Edge):代表执行流程与状态流转
- 图(Graph):定义 Agent 如何在节点之间流动、推理和决策
所以 LangChain 的每个 Agent 都是一张有向图,语言模型是推理引擎,工具是行动节点,底层通过 LangGraph 进行编写和实现。
联网查询功能
LangChain 内置了 TavilySearchResults 搜索工具,可以借助 Tavily 进行网络搜索和信息爬取:
1
2
3
4
5
6
|
from langchain_tavily import TavilySearch
import os
os.environ["TAVILY_API_KEY"] = 'xxx'
search = TavilySearch(max_results=2)
result = search.invoke("今天上海的天气怎么样")
|
将普通函数包装成 Tool 对象即可让大模型调用,需要将函数功能、输入参数和返回值的数据格式与变量内容描述清楚:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
from langchain.tools import tool
@tool
def get_weather(loc: str):
"""
查询即时天气函数
:param loc: 必要参数,字符串类型,用于表示查询天气的具体城市名称,
注意,中国的城市需要用对应城市的英文名称代替,例如查询北京市天气,则loc参数需要输入'Beijing'
:return:OpenWeather API查询即时天气的结果,返回解析之后的JSON格式对象
"""
url = "https://api.openweathermap.org/data/2.5/weather"
params = {
"q": loc,
"appid": os.getenv("OPENWEATHER_API_KEY"),
"units": "metric",
"lang": "zh_cn"
}
response = requests.get(url, params=params)
data = response.json()
return json.dumps(data)
|
1
2
3
|
print(get_weather.name)
print(get_weather.description)
print(get_weather.args)
|
在 LangChain 中,已经自动处理了并行工具调用的处理逻辑,不需要手动处理。增加一个查询当前时间的函数,尝试让大模型同时查询时间和天气并汇总结果:
1
2
3
4
5
6
7
8
9
10
11
|
import datetime
@tool
def get_current_time():
"""
可以获取当前时间
:return: current_time 获取当前本地时间,返回格式:YYYY-MM-DD HH:MM:SS
"""
current_dt = datetime.datetime.now()
current_time = current_dt.strftime("%Y-%m-%d %H:%M:%S")
return current_time
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
system_prompt = '你是一名助人为乐的助手,并且可以调用工具进行查询,获取实时信息。'
tools = [get_weather, get_current_time]
agent = create_agent(
model=model,
tools=tools,
system_prompt=system_prompt,
)
response = agent.invoke(
{"messages": [{"role": "user", "content": "现在时间是多少?今天上海的天气怎么样?"}]}
)
for res in response['messages']:
print(res.__class__)
|
在 LangChain 框架的 Agent 中,模型有能力进行 ReAct,在每一步执行过程中会自主思考调用工具的路径:
1
2
3
|
response = weather_agent.invoke(
{"messages": [{"role": "user", "content": "今天北京和上海的气温是多少?"}]}
)
|
输出结果:
1
2
3
4
5
6
|
<class 'langchain_core.messages.human.HumanMessage'>
<class 'langchain_core.messages.ai.AIMessage'>
<class 'langchain_core.messages.tool.ToolMessage'>
<class 'langchain_core.messages.ai.AIMessage'>
<class 'langchain_core.messages.tool.ToolMessage'>
<class 'langchain_core.messages.ai.AIMessage'>
|
两个 ToolMessage 之间有一个 AIMessage,代表大模型在这个流程中进行规划推理(ReAct),让模型串行调用工具。
可以再写一个函数,将模型返回的内容写入本地文档,这就需要串行进行,先进行查询,再将查询的内容写入文档:
1
2
3
4
5
6
7
8
9
10
11
|
@tool
def write_file(content: str) -> str:
"""
将指定内容写入本地文件。
:param content: 必要参数,字符串类型,用于表示需要写入文档的具体内容。
:return:是否成功写入的提示字符串
"""
file_path = os.path.join(os.getcwd(), "weather.txt")
with open(file_path, "w", encoding="utf-8") as f:
f.write(content)
return '文件已经写入当前目录'
|
1
2
3
4
5
6
7
8
9
10
11
|
tools = [get_weather, write_file]
weather_agent = create_agent(
model=model,
tools=tools,
system_prompt=system_prompt
)
response = weather_agent.invoke(
{"messages": [{"role": "user", "content": "今天上海和北京的天气怎么样,并写入本地"}]}
)
|
可以看到模型调用了三次 tool:第一次和第二次是查询天气,然后 Agent 对获取的天气内容进行总结,第三次调用工具是把总结的内容写入本地文件。
附录:LangChain 内部工具
| 领域 |
工具名称 |
功能说明 |
| 搜索引擎 |
DuckDuckGo Search |
免费搜索引擎,返回网页标题、摘要与链接 |
|
Bing Search Tool |
微软 Bing 搜索接口,支持精确检索与多语言查询 |
| 网页浏览 |
Playwright Browser Toolkit |
浏览器自动化访问、网页截图与文本抓取 |
|
Selenium Toolkit |
传统网页 DOM 操控 |
| 生产力工具 |
Slack Toolkit |
在 Slack 中发送、读取或总结消息 |
|
Jira Toolkit |
查询、创建或更新 Jira 项目工单 |
|
Google Drive / Docs Toolkit |
操作 Google 文档、表格与文件搜索 |
| 数据库 |
SQLDatabase Toolkit |
连接 SQL 数据库,自动生成并执行 SQL 查询 |
|
Faiss / Chroma / Milvus VectorStore Tools |
向量相似度搜索,用于 RAG 检索 |
| 代码执行 |
Python REPL Tool |
执行 Python 代码片段并返回结果 |
|
Shell Tool (Bash) |
执行 Shell 命令 |
| 多模态 |
DALL-E Tool |
生成图像 |
|
OpenAI Whisper Tool |
音频转录工具 |
| 知识问答 |
VectorStoreRetrieverTool |
基于嵌入模型检索文档片段,用于 RAG 问答 |